Scalaでイミュータブルなエンティティを実装する
この記事はScala Advent Calendar 2019 - Qiitaの13日目の記事です。
Scala界隈にはドメイン駆動設計を実践されている、または導入を検討されている方が多いかと思います。筆者が携わっているScalebaseプロジェクトでも、バックエンドAPIの実装にScalaを採用しつつドメイン駆動設計を念頭に開発を進めています。
今回はその試行錯誤の経験の中から、Case Classを用いたイミュータブルなエンティティの特性について、感じたことを共有したいと思います。
ミュータブルなエンティティ
『エリック・エヴァンスのドメイン駆動設計』では、システムが同一性を考慮しなければならないエンティティと、同一性を考慮しなくてよい値オブジェクトを区別して設計することが強調されています。エンティティは概念的に「変化するもの(ミュータブル)」であり、値オブジェクトは一度生まれたら「変化しないもの(イミュータブル)」です。
同一性を考慮する必要があるというのは、例えば現実世界の人間のように、身長、体重、年齢、健康状態、あるいは名前が変わったとしても、「同一の人間である」と捉えるべき存在であるということです。しかし、システム上は必ずしも人間がエンティティであるとは限りません。例えば映画館の来場者の数や属性を記録するだけのシステムでは、人間を表す値オブジェクトを設計するのが妥当な判断になるかもしれません。何をエンティティとして扱うべきかは、作っているアプリケーションによって異なるのです。
別の例としては、「銀行口座」もシステム上でエンティティとして扱われることが多い概念でしょう。今あなたは「口座管理システム」の設計を任されているとします。このシステムでは各口座の同一性を認識し、どの口座に、どの通貨が、いくら預けられているかを記録しておく必要があります。
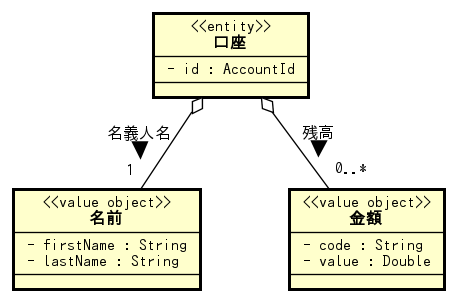
一般的には同一性を確認するために一意な識別子(ID)を設け、データベースのユニーク制約などを用いて、システム内に同一のIDを持つエンティティがただ一つであることを保証することになるでしょう。上のUMLは「名前」と「金額」を表す値のグループを、それぞれ値オブジェクトとして定義することを示しています。また、口座IDも専用のクラスを設けて値オブジェクトにしています。まずはこれをScalaのクラスで表現してみましょう。
class Account( val id: AccountId, // 口座のID private var ownerName: Name, // 名義人名 private var balances: Map[String, Money] = Map() // 通貨毎の口座の残高 ) { assert(balances.forall(_._2.value >= 0), "残高が0未満になることはない") def getOwnerName: Name = ownerName def getBalances: Map[String, Money] = balances def changeOwnerName(newName: Name): Unit = { ownerName = newName } def addMoney(newMoney: Money): Unit = { val existingMoney = balances.getOrElse(newMoney.code, Money(newMoney.code, 0)) balances = balances + (newMoney.code -> existingMoney.plus(newMoney)) } } case class AccountId(value: Int) // 口座IDを表すVO case class Name(firstName: String, lastName: String) // 名前を表すVO case class Money(code: String, value: Double) { // 金額を表すVO def plus(other: Money): Money = { require(other.code == code, "同じ通貨のみ加算できる") copy(value = value + other.value) } }
IDが変化してしまうと同一性を認識できなくなるので、そこだけは定数とし、他のプロパティは全て変数としています。この形は「概念的に」ミュータブルであるエンティティを、コード上でもミュータブルなものとして表現しています。インスタンスを作り、リポジトリに永続化するコードは以下のようなイメージです。
val account1 = new Account(AccountId(1), Name("太郎", "山田"), List()) account1.addMoney(Money("JPY", 100.0)) accountRepository.store(account1)
ミュータブルな実装であれば、復元したエンティティに対して変更を加え、再度保存するというようなコードが素直に書けます。
val account1 = accountRepository.findById(AccountId(1)) account1.changeOwnerName(Name("次郎", "山田")) account1.addMoney(Money("USD", 1.0)) account1.addMoney(Money("EUR", 2.0)) accountRepository.store(account1)
さらにリポジトリにIdentity Mapパターンを組み込めば、同一のIDのエンティティがスコープの中にただ一つしか存在しないように保証することも可能です。もし同一のIDのエンティティが複数同時に存在するようなコードを書いてしまった場合、どれを保存すれば最新の状態が記録されるか判別が困難になるため、これは重要なポイントです。
イミュータブルなエンティティ
しかし、Scalaの入門書では「可能な限りイミュータブルなデータ構造を使うこと」、そして「varではなくvalを使うこと」が推奨されていることが多いと思います。その理由は、変数を減らすほど読解が容易で不具合が少ないプログラムにできること、並列処理の実装の難易度が低くなること、関数型プログラミングでは参照透過性が重要になることなどがあるでしょう。ではその助言に従ってAccountクラスをイミュータブルにしてみましょう。ここでは記述量を減らすためにCase Classを使います。
case class Account2( id: AccountId, ownerName: Name, balances: Map[String, Money] = Map() ) { assert(balances.forall(_._2.value >= 0), "残高が0未満になることはない") def changeOwnerName(newName: Name): Account2 = { copy(ownerName = newName) } def addMoney(newMoney: Money): Account2 = { val existingMoney = balances.getOrElse(newMoney.code, Money(newMoney.code, 0)) copy(balances = balances + (newMoney.code -> existingMoney.plus(newMoney))) } }
全てのプロパティは定数になります。また、プロパティを書き換えるメソッドは自身のコピーを返却するメソッドに変わっています。コマンドクエリ分離の原則から考えると、コマンドがクエリに変化したようにも見えます。
クラス定義の記述量は減りましたが、厄介なのはエンティティの状態を変化させるコードです。先程の「復元・変更・再保存」のコードを愚直に書き換えると、以下のような煩雑なコードができあがります。
val account1 = accountRepository.findById(AccountId(1)) val account2 = account1.changeOwnerName(Name("次郎", "山田")) val account3 = account1.addMoney(Money("USD", 1.0)) val account4 = account3.addMoney(Money("EUR", 2.0)) accountRepository.store(account4)
先程との大きな違いはスコープの中に同一のIDのエンティティがいくつも存在していることです。プログラマは常に最新のエンティティがどれであるかを意識し、それに対してのみメソッドを呼び出し、必ず最後に生まれたオブジェクトをリポジトリに渡す必要があります。そうしなければ、途中の変更がロストしてしまいます(よく見ると上記のコードには、名前の変更が保存されないというバグがあります)。また、こちらの実装方法では次々に新しいオブジェクトが生まれるため、Identity Mapのようなオブジェクトへの参照を使ったデザインパターンの適用は不可能になります。
これは「概念的に」ミュータブルであるエンティティを、コード上ではイミュータブルなオブジェクトとして扱わなければならないという、認知的負荷の増大を意味しているとも言えそうです。ただしそれが問題になるのは、上記のコードが上から順にデータを書き換えていく手続き型のアプローチから脱却できていないせいかもしれません。関数型プログラミングのアプローチを使えば、この手の負荷を軽減することは可能だと思います。ScalebaseプロジェクトではEffを用いて関数型プログラミングを取り入れているのですが、同一性に関する煩わしさが問題になったことはほとんどありません。
ではさらに設計を複雑にして、集約のルートエンティティについて考えてみましょう。
イミュータブルな集約のルートエンティティ
口座エンティティは単独で永続化・復元のライフサイクルを持つので、集約のルートエンティティになっているようです。しかし、今の構造では取引の履歴を持てないので、取引エンティティを口座集約の中に持たせて履歴を残せるようにしてみます。
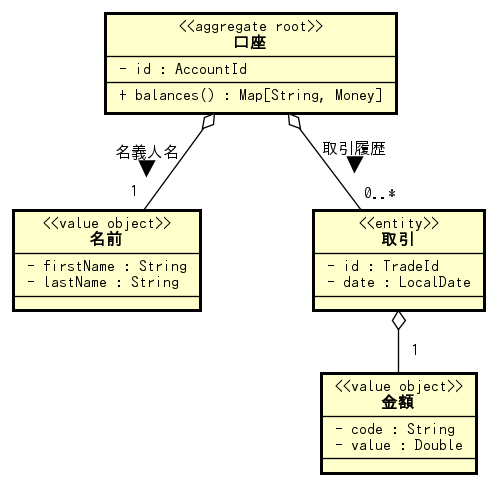
まずは取引のエンティティをコードにしてみましょう。取引は「いつ取引したのか?」「いくら取引したのか?」という情報を保持します。また、銀行員の入力ミスを想定して、無効化できるようにしておきます(ただし削除はできません)。
case class Trade( id: TradeId, date: LocalDate, money: Money, disabled: Boolean = false ) { def disable: Trade = copy(disabled = true) } case class TradeId(value: Int)
次に口座のエンティティです。新しい口座クラスは残高をプロパティとして持つのではなく、取引の履歴から動的に算出するようにします。こうすれば、取引の追加や無効化の際に残高を更新する必要がなくなります。また、すでにbalancesプロパティに依存したコードがあったとしても、それらが影響を受けることはありません。これはScalaが統一形式アクセスの原則を満たせる構文になっている恩恵です。Scalaは関数型プログラミングの側面が取り上げられることが多いですが、こうしたオブジェクト指向プログラミングの要所もしっかり押さえているのが良いところだと思います。
case class Account3( id: AccountId, ownerName: Name, tradeHistory: List[Trade] = Nil ) { assert(balances.forall(_._2.value >= 0), "残高が0未満になることはない") def changeOwnerName(newName: Name): Account3 = copy(ownerName = newName) def addTrade(newTrade: Trade): Account3 = copy(tradeHistory = (newTrade :: tradeHistory).sortBy(_.date)) def balances: Map[String, Money] = tradeHistory .filterNot(_.disabled) .groupMapReduce(_.money.code)(_.money)(_.plus(_)) def disableTrade(tradeId: TradeId): Account3 = copy(tradeHistory = tradeHistory.map { trade => if (trade.id.equals(tradeId)) trade.disable else trade }) }
Scalaが備えるオブジェクト指向プログラミングの特性として、もう一つ便利なものが表明(アサーション)です。集約を設計する際、肝心なのは不変条件がなにかを考えることです。口座集約の場合、「どのような取引をしても、各通貨の残高は0未満にならない」という不変条件があるでしょう。表明を使えば、この不変条件を「動くドキュメント」として記述することが出来ます。集約と表明の関係について、筆者の考えはこちらの記事でまとめています。
この記事では堅牢な集約を実装する上で守るべき原則として、以下の事項を挙げました。
- 集約のルートエンティティは、集約全体の不変条件を守る責務を持つ
- 集約のルートではないエンティティのコマンドは、集約の外から呼び出してはならない
これらを守るにはどうしたら良いでしょうか? Account3のコードをもう一度よく見てみてください。実はこのコードはすでに、これらの原則を自動的に守れる状態になっているのです。一つずつ見ていきましょう。
まず、1つめの原則について。Account3のインスタンスの状態を変えるメソッドは、常にcopyを使って実装されています。Account3のコンストラクタを呼んでいても良いのですか、いずれにせよ必ずアサーションのコードを通過することになります。そのため、以下のようなコードでは表明例外が発生します。
val account = Account3( AccountId(1), Name("太郎", "山田"), List( Trade( TradeId(1), LocalDate.parse("2019-12-01"), Money("JPY", 1000) // 1000円の入金 ), Trade( TradeId(2), LocalDate.parse("2019-12-01"), Money("JPY", -500) // 500円の引き出し ) ) ) // 1000円の入金をなかったことにする account.disableTrade(TradeId(1)) // Exception in thread "main" java.lang.AssertionError: assertion failed: 残高が0未満になることはない
表明を使えばビジネスルールとして本来許容されないコードを書いてしまっても、すぐにそれに気づくことができます。ただし、ユーザーの不正な操作を検知してエラーを排出することと混同しないように注意してください。表明例外はプログラマのミスであり、コードの不具合です。表明例外の発生を検知したら、次に取るべき行動はバグの修正です。
では2つ目の原則も検証してみましょう。試しにルールを無視して取引エンティティの無効化のコマンドを、ルートエンティティの外から呼んでみます。何が起きるでしょうか?
val account = ...
account.tradeHistory.headOption.map(_.disable)
このコード何も変化させません。メモリ上に無意味な取引のコピーが生まれ、ただ消えるだけです。そもそもdisableはコマンドクエリ分離原則の定義からすると、コマンドではなくクエリになっています。集約の状態を変化させる方法は唯一つ、ルートエンティティのインスタンスメソッドを呼び出して、その結果を保存することだけなのです。*1
まとめ
どうやらScalaでイミュータブルなエンティティを実装すると、以下のようなメリットとデメリットがあるようです。
- 手続き的なコードの上では認知的負荷が高まり、不具合の原因にもなりやすい
- 同一性を扱うOOPのデザインパターンが一部適用不能になる
- Case Classを使った場合、クラス定義の記述量を削減できる
- 表明と組み合わせることによって、集約の不変条件を容易に維持できる
いかなる状況でもエンティティをイミュータブルにすべきとまでは言えませんが、関数型のアプローチを採用するプロジェクトでは十分理に適った選択になるのではないでしょうか。単にScalaの慣習としてだけではなく、堅牢な集約を設計する上でもメリットがあると言えるでしょう。一方で、ScalaをBetter Javaと捉えているプロジェクトでは、ミュータブルなエンティティを設計したほうが素直なコードになることもありそうです。
明日はshowmant - Qiitaさんが何か書くそうです。